This page contains all of the information from the website for the old version of MEH (i.e., MEH version 1.4.31 and older). This version of MEH is no longer supported, however, it is still completely free for you to use and enjoy.
DOWNLOAD
All information below this point pertains to the older version of MEH.
Download Older Version
MEH is a Windows-only application at the moment, and it requires that you install version Microsoft .NET 4.6.2 installed. This can be downloaded from the official Microsoft webpage, located here:
https://www.microsoft.com/en-us/download/details.aspx?id=53344
To download the older version (Version 1.4.31), choose your preferred version:
MEH Installer for Windows — (download)
Portable Version (non-installer version) — (download)
Additional Notes
For Mac Users: If you are a Mac user, I’m sorry! MEH is a window-only utility. However, you can still easily use the portable version (above) on a Windows machine of your choice (or a Windows Virtual Machine). Extract the contents of the .zip file to a thumb drive (make sure that all files are in the same folder). You can then run the portable version from a thumb drive on a Windows machine. This has also been successfully tested on Windows 7 running under both BootCamp and Parallels 9 on a Mac. If you need a portable version that will run on a Windows XP machine, please send me an e-mail and I will gladly build one for you.
As a note, the portable version may run more slowly from a thumb drive, especially if your data is also located on a thumb drive.
For users running Windows XP: I have decided to stop building versions specific to Windows XP, as they do not appear to be downloaded frequently and it takes a considerable amount of time to create additional builds. If you would like a copy of the newest version that can run on Windows XP, please send me an e-mail and we can work something out.
DISCLAIMER!! By downloading and/or using any of the software on this page, you acknowledge that this software is ONLY A TOOL to help you with your statistical analyses. You are ultimately responsible for ensuring that your analyses are correct. I assume no liability, direct or otherwise, that may result from your use of the software on this page.
In order to install MEH, simply download the latest version and double-click the file in order to launch the setup program. This program will guide you through the steps; changing the default settings is not recommended for most users. Note: Previous versions of MEH must be removed prior to installation.
In order to uninstall, locate the “MEH” folder in your Start Menu and click on “Uninstall MEH”. Alternatively, this task may be accomplished through your Control Panel under “Add/Remove Programs and Features”.
GENERAL USE
Step 1: Selection of Files
Upon opening the Meaning Extraction Helper (MEH), the first thing that you will want to do is specify the location of your text files. MEH is designed to cleanly read text stored inside of .txt files with various encodings. In order to select your desired files for analysis, click on the Select Folder button on the top left portion of the program. You will be prompted to select which folder you would like to open, and MEH will scan the folder for .txt files that it will include for analysis. Once you have located the folder that you would like to analyze, press the OK button.
Step 2: Language Manipulation Selections
MEH engages in a rigorous and thorough removal of extraneous characters from your text prior to all scanning and processing, helping to ensure the most streamlined process leading up to the meaning extraction method. However, you will most likely want to make additional changes to the text prior to all analyses such that common concepts are recognized as the same, and removing extra words (known as “stop words”) that are traditionally of little value to content and meaning extraction. This section will only cover the basics of this process. For advanced use of these features, please refer to the “Advanced Conversions” page.
For basic use, you will simply want to load the default MEH stop word and conversion lists. To do this, simply use the Language Selection panel to select your desired language.
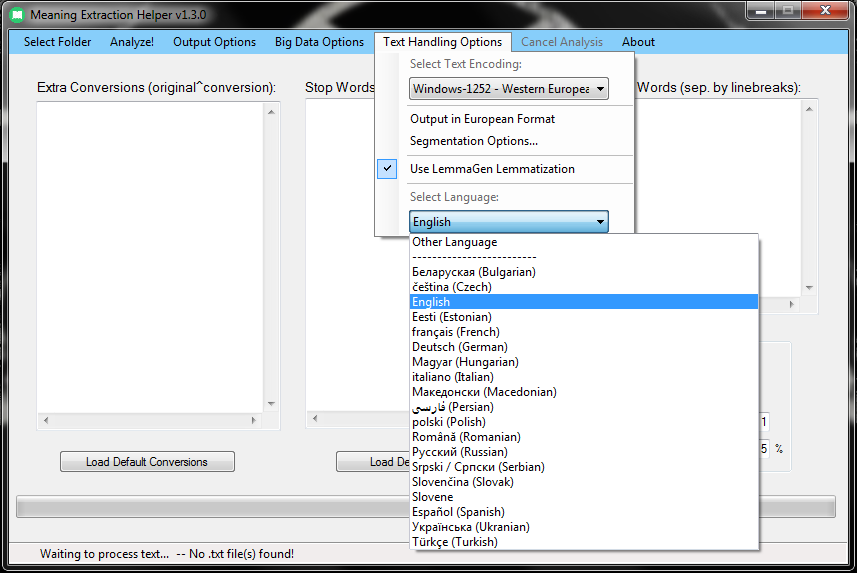
Once your desired language is selected, simply press the Load Default Conversions and Load Default Stop Words buttons.
![]()
![]()
These buttons will populate the corresponding boxes with the default lists that are built into MEH. You may edit these lists to your specific needs, and capitalization is not important for these lists. NOTE: These lists are not comprehensive, and are still under development for multiple languages. If you would like to contribute to this process, please e-mail the author of this software. You will be listed as a contributor on this website.
Finally, users interested in performing the Meaning Extraction Method will likely want to perform lemmatization. In order to do this, ensure that the LemmaGen Lemmatization 3.0 checkbox is still selected.
![]()
Step 3: Selecting Options
If you are interested in only performing a frequency analysis, you need only to specify this by using the “Options” menu and making sure that only “Generate Frequency File” is checked. Afterwards, you may continue on to the Step 4. If you want to perform the Meaning Extraction Method, however, you should select some of the other output checkboxes, such as “Generate Binary Output” and “GenerateVerbose Output”.
Now that you have selected the language manipulation options that you intend to use, you should select the appropriate options for performing the Meaning Extraction Method. For basic uses, the MEH defaults should be adequate. For more advanced uses, please refer to the “Options” page.
Step 4: Analyzing Your Text
Once you have reached this step, you are ready to have MEH process your text. In order to do this. Click on the Analyze! button to begin this procedure.
MEH will then ask you where you would like to place your output.
Once you have selected where you would like for your output to be generated, click the OK button to proceed. MEH will now make two passes through the text that you supply. The first pass is to run a frequency analysis, the second pass is to run a content analysis. This procedure will overwrite preexisting data that shares the same name as the output data, so make sure that back up previous analyses in another location. You may press the Cancel button at any time to halt analysis if you need to do so.
Once processing is complete, you will receive a notification. You now have your complete analysis! Afterwards, you are ready to begin your PCA!
OPTIONS
Conversions:
Conversions take place prior to lemmatization when text is being processed; this feature is intended to augment and assist lemmatization. Additionally, this feature allows the user to customize text replacement. The “Conversions” field may be used to fix common misspellings (e.g., “hieght” to “height”; “teh” to “the”), convert “textisms” (e.g., “bf” to “boyfriend”), and so on. The conversions feature also allows for wilcards (*).
The proper format for conversion is:
(original)^(converted form)
Example:
bf^boyfriend
This will replace all occurrences of the word “bf” with “boyfriend” before analyzing text. As a note, original and converted forms need not be a single word (e.g., “MEH is awesome” to “This software is adequate”). For more advanced uses and a deeper explanation of using the conversion engine, please refer to the “Advanced Conversions” page.
Stop Words:
You may read more about using stop words here. The only point of note here is that “QQNUMBERQQ” is used to represent all numeric values in the text. This will show up as “#” in the frequency analysis.
Dictionary Words:
“Dictionary Words” are user-specified words to include, even if they are low base-rate words. Dictionary Words can be rather multipurpose in nature, and it can be used in multiple ways depending on your intent. For example, if you are looking to search a corpus of text for specific words in specific observations to look for differences, Dictionary Mode works nicely for this. Another example of its use is as follows: if you scan one corpus and get the most common words, you can copy/paste the words from this frequency list into the Dictionary List to search a new corpus for the same words.
An additional example of Dictionary Words use is to code text into a categorical fashion, similar to software like LIWC. For example, if you would like to code words into positive and negative emotion categories, you could do this coding in the Extra Conversions box.
happy^posEmotion
happ*^posEmotion
surpris*posEmotion
sad^negEmotion
depress*^negEmotion
furious^negEmotion
Following this, you could simply include “posEmotion” and “negEmotion” in your dictionary list. This will result in output that codes for all of the words specified in your conversion list, aggregated into the categories specified in your dictionary list. Note that if you use this feature for content coding, you will want use conversions that result in strings that don’t appear in your files. For example, if you convert all positive emotions words to “PosEmoCoded”, you are probably safe. If you convert all positive emotion words to the word “up”, you are going to have a bad time.
Note: If you input words into the Dictionary Words box, MEH will automatically adjust the N-grams and [N-X]-grams to correspond with your list right before analyses. This is done so that multi-word phrases, etc., in your dictionary list are not missed due to an incorrect setting.
Search Files for N-grams:
This option allows you to choose the “window” of words for which you would like to scan in terms of N-grams. The default is 1-grams, and this is strongly recommended for the meaning extraction method. The user may specify up to 5-grams, as this may be useful for frequency analyses. Be advised that with each progressive N-gram, the time that it takes to construct a frequency table grows exponentially.
Include [N-X]-grams:
If you are scanning for N-grams that are larger than 1 (e.g., 2-grams, 3-grams, etc.), you may also want to scan for “sub”-grams. In other words, if you are scanning for 3-grams, you may also be interested in the 2-grams and 1-grams that are present. Selecting this option will tell MEH to include these [N-X]-grams in your frequency list and other output.
Minimum Obs. Word Count
This field will exclude observations from the content analysis portion of the meaning extraction helping process. Observation word counts are determined after conversions and lemmatization have been applied. Note: To be clear, this value will not impact the frequency analysis, only the content analysis portion of the process.
Minimum Obs. Percentage
Following the frequency analysis, this number will be used to specify the percentage of observations in which an N-gram must appear for it to be included in subsequent steps (such as rescanning and dictionary construction). Your observation percentages will change if you use segmentation since segmentation and minimum word counts will change your final number of observations. (see Understanding Output).
This value can be used to follow standard guidelines (e.g., 5% and above) that have been recommended for performing the meaning extraction method.
Use Existing T-D Freqs / Freq List:
This option allows you to start from a term-frequency folder and (if desired) a frequency list that has already been generated by MEH. This option may be useful if you need to restart or rerun an analysis for which you have already obtained frequency data, allowing you to expedite the process. It is important that your frequency list contains the metadata that is provided by MEH 1.0.5 and later versions (see Understanding Output). You will also need to let MEH know where your Term Frequency folder is located. This folder is used in further steps.
Freq. List Generation Options
For most users, it will be completely unnecessary to change these options. However, if the “Building Combined Frequency List” phase of your analysis is running particularly slowly, you should consider reading the details of these options to find better settings.
Newer versions of MEH have been designed with larger datasets in mind. This is true from both the standpoint of breadth (i.e., an extremely large number of files) and depth (i.e., files that have a lot of text). After creating Term Frequency files, MEH needs to recombine this information in order to figure out how many times each word appears, and in what percentage of observations. In order to achieve this relatively quickly, MEH makes several passes over your Term Frequency information, combining it as efficiently as it can, then by writing temporary information to your hard drive. Each pass is set up to combine certain amounts of data and, after several passes, this data will be effectively reduced to the final frequency list.
In this section of the options, you will see a slider that reads “Items to Incorporate per Pass“. If you know that your text files are very large, you may consider setting this to a very low value as this will result in faster data combination. If you know that you have an extremely large amount of very small files, you should consider setting this to a higher value. A related option reads “Decrement Value After Each Pass” — this option will help the later passes to combine information more quickly.
An alternative to these options is to have MEH “Dynamically Adjust These Values“. This option will use a simple algorithm to automatically decide how much data to combine at any giving point as an attempt to improve the efficiency of the frequency list generation phase. This option also allows you to specify how “strict” the algorithm will be, with greater strictness requiring more passes but potentially making the overall process more speedy. Preliminary benchmarking suggests that speed of this stage of analysis can be improved by up to approximately 20% with this option. However, the degree to which this algorithm can be efficiently applied to various datasets is currently untested.
Prune Low Baserate N-Grams
This option can help to minimize the amount of time that it takes to build your frequency list and, additionally, can help keep your frequency list size manageable. This is particularly true for very large datasets (either in terms of the number of files or the sheer amount of words in each file).
The way that this option works is that it will selectively omit n-grams while combining information from all of your text files. You will need to specify two things:
- The pass number at which you would like to start pruning low baserate n-grams
- The minimum frequency an n-gram must have (at your specified pass) in order to be retained
This option, if selected, will kick in during the “Building Combined Frequency List” phase, when MEH is merging together information from all of your files. For example, let’s say that it takes 20 complete passes over your files to build your entire frequency list. You can specify to MEH that you want to omit any n-grams that have not occurred in your dataset at least 5 times in any given subset of your data by the 3rd pass. Once MEH hits the 3rd pass, it will start to prune off n-grams that occur below this threshold in each chunk of data that it is combining.
Note that using this option will give you less accurate numbers for low baserate n-grams, but will not impact moderately common or high baserate n-grams. Essentially, if you want to have a complete and comprehensive frequency list, you should not use this option. However, if you do not intend to use very uncommon words and do not mind that uncommon words exhibit some degree of under-representation, then this option is ideal. This is particularly true for very large datasets, as the “Building Combined Frequency List” phase can take extremely long given that there will be a massive number of n-grams that appear only a few times in your entire corpus — this is consistent with Zipf’s Law.
Select Text Encoding
The encoding option allows you to select how you would like for your text files to be read, as well as how you would like for your output files to be written. For most cases, you will likely want to use the your system’s default encoding (which MEH detects and selects by default). If you are experiencing odd characters or broken words in your output, this is likely being caused by a mismatch between your selected encoding and the encoding used for the text files. In these cases, you may want to consider examining your text files and selecting the appropriate encoding.
Lemmatization:
Lemmatization using the LemmaGen engine is recommended for the meaning extraction method. You may read more about lemmatization here. Note: For various reasons, such as part-of-speech ambiguity in lieu of context, some words are not converted to potential lemmas during lemmatization. See the “Conversions” feature for additional details.
Output in European Format
This option will ensure that the primary output files are able to be read as proper .csv files on computers with a region set to European. These files have a slightly different internal format, ensuring that columns are properly delimited for computers set to this region.
“Big Data” Settings
MEH is in many ways designed with your “big data” needs in mind. The two options included for big data are “On The Fly” Folder indexing and subfolder scanning.
Subfolder scanning will allow MEH to crawl through all subfolders of the primary folder that you have specified to find all .txt files in the directory tree and include them in your analyses. This is particularly useful if you are working with a large dataset, where it is usually best to divide observations into between 10,000 and 25,000 files per folder. As an example, a single folder containing 22,000,000 text files is effectively beyond the current capabilities of the Windows operating system, and you will not be able to peruse a folder that is this full, let alone analyze it effectively or rapidly. However, if you divide these text files into 800+ folders of 25,000 files each, both MEH and you will be able to quickly and easily access each folder and set of files without putting undue strain on the Windows OS.
Indexing folders “on the fly” can save a considerable amount of time if you are working with an extremely large number of text files as well. For example, pretend that you have a dataset with 500,000 text samples, divided into folders of 25,000 text samples each (i.e., 20 folders, each containing 25,000 files). Normally, MEH would go through each folder to determine the total number of files, create a temporary index of all .txt files, and then proceed with analysis. Indexing folders “on the fly”, however, will start the analysis procedures immediately, and will do its best to index each folder of text samples in turn as it proceeds, rather than all folders at once. This option is highly recommended for situations such as this, as indexing files ahead of time is not a useful exercise when there are so many of them. Note that you might see MEH pause for some time while performing analyses as it moves from location to location — this is normal, and MEH is working correctly.
Number of Processor Cores to Use
If you have a multi-core processor in your computer, or you have multiple processors, MEH can take advantage of your hardware to process multiple files at the same time. This results in much faster analyses and can be extremely useful for large datasets. If you notice considerable slow-down or freezing of the interface when processing texts, you might need to lower the number of cores being used by MEH.
Skip files that cannot be opened/read
This option is included for people working with large datasets that have a lot of issues. For example, many datasets might have series of corrupted text files that were improperly written to disk. By checking this option, MEH will not get stuck in a “retry/cancel” state for a file that it cannot read. Rather, it will attempt to open the file and, if this fails, the file will be treated as empty.
SEGMENTATION OPTIONS
Split Files into Equally Sized Segments:
This option allows you to uniformly split all incoming files into the same number of segments. For example, if you want to split all text files into 10 parts, this option will accomplish this. Each segment within each file will be approximately the same size.
Desired Segment Size:
This field allows you to specify what your desired maximum segment size will be when processing text. Use the default value of zero to refrain from segmenting text. Your text files will be smartly parsed so that segments are as equally close to your desired target size as is possible.
This option may also be thought of as a word count normalization tool, as well as a word count upper boundary limitation. This feature is of great use when the files that you would like to process are of varying word counts. The Meaning Extraction Method is optimal when word counts across observations is relatively homogenous. When using this option, no segments will exceed the limit that you place in this field. For example, a target segmentation size of 150 will parse files in such a manner:
An 80-word observation remains at 80 words.
A 300-word observation becomes 2 150-word segments.
A 500-word observation becomes 4 segments, each containing approximately 125 words.
Note: If any observation becomes segmented, its segments will never fall below 50% of the limits specified by this option. Observations that already fall below the target segmentation specified by the user will remain unsegmented at their original word count.
Think of engaging in the meaning extraction method as a bit like tuning an oscilloscope. You have two knobs that you are trying to tweak to find the “best” possible theme solution. You will want to tune your “wave amplitude” knob (i.e., the segment size / word count normalization) and then try to find the right “wave frequency” (i.e., various PCA solutions). Turn your “amplitude” knob to a good spot, then try adjusting the frequency. If you are getting a “noisy” signal, then try changing the amplitude, then adjust your frequency some more.
Segment Text with Regular Expression:
This allows you to enter a regular expression that will be used to determine where to segment texts. For example, if you want to split your text files by paragraph, you might use the regular expression rn for newline splits. This option is also useful for building semantic network data, be it at the paragraph level (\r\n), sentence level, etc. Every time a match is found in with your expression, a split will be placed in that location. Also useful for other topic modeling methods, such as LDA, if you are looking for a specific level of analysis.
ADVANCED CONVERSIONS
Conversions take place prior to lemmatization when text is being processed; this feature is intended to augment and assist lemmatization. Additionally, this feature allows the user to customize text replacement. The Conversions panel may be used to fix common misspellings (e.g., “hieght” to “height”; “teh” to “the”), convert “textisms” (e.g., “bf” to “boyfriend”), and so on. The conversions feature also allows for wildcards (*).
The proper format for conversion is:
(original form)^(converted form)
Example:
bf^boyfriend
This will replace all occurrences of the word “bf” with “boyfriend” before analyzing text. Additionally, original and converted forms need not be a single word, as MEH is able to perform phrase conversions as well (e.g., “MEH rules!” to “This software is adequate”). Note: Capitalization does not matter for conversions.
More Examples:
dream*^dream
*estimat*^estimate
I * you^social_phrase
In the above examples:
Words such as “dreaming” and “dreamt” are converted to “dream”.
Words such as “underestimate” and “overestimation” are converted to “estimate”, due to the use of wildcards (*) at the beginning and end.
Phrases such as “I love you” and “I know you” are converted to “social_phrase”.
This last example is of particular importance for users who wish to reconstrue the meaning of specific words or phrases for conceptual reasons in their frequency analyses, meaning extractions, or both. For example, if you are interested in extracting meanings pertaining to emotions broadly defined, rather than specifics, you may consider adding extra conversions such as the following:
happy^emotion
sad^emotion
anger^emotion
excite*^emotion
fear*^emotion
This list would convert all words listed, including words picked up with wildcards (e.g., “fearfulness” and “excitement”) to the word “emotion”. This would allow for the user to look at the ways in which the emotional concepts correspond to other content words as per the standard meaning extraction method. Such additional conversions will also be accounted for during the construction of an external dictionary, if this option is selected.
UNDERSTANDING OUTPUT
Term Frequency Files
Since version 1.2.0, these files are a crucial part of how MEH functions. These files provide basic information about each text file that you are processing. Namely, this includes the word count (calculated after conversions and lemmatization, but before stop-word removal) and Term Frequency information for each document.
Important: It is vital that you do not alter or move these files while your text is processing. Doing so may cause your results to be incomplete or incorrect. It is also important that you save these files if you intend to reuse your frequency list after all of your text has been initially processed. I would recommend using a compression program, such as 7-Zip for Windows or Keka for Mac, to store these files at low cost to your hard drive space.
Frequency Table
By default, MEH will output an N-gram frequency table after performing the initial analysis. This file will contain a complete list of all N-grams and their corresponding frequencies in your data — this information is counted in two different ways. The first way is reflected in a column labeled “Total_Frequency” — this is the overall frequency of each n-gram in the entire dataset. The second way is reflected in a column labeled “Included_Frequency” — this is the frequency of each n-gram, excluding observations that fall below your specified minimum word count. This table will reflect your data after accounting for any conversions, stop words, and lemmatization features that you have selected.
Your frequency table will also include both the raw number, as well as the percentage, of observations that the N-gram appears in. Remember, your total number of observations will vary depending upon your choices in segmentation and minimum word count cutoffs, which will then invariably alter your observation percentages. It is possible to get a 0% in this column for a given N-gram — this will happen when an N-gram is detected by frequency analysis yet does not occur in a file/segment that meets your minimum WC cutoff value. This area of the frequency list will also include the IDF, or “inverse document frequency“. This data can be paired with your Document Term Matrix (DTM) output file to easily create a dataset in TF-IDF format, which may be useful for various procedures.
Finally, the frequency table will also include metadata about the values used when it was created, as well as the final number of observations included. Since the observation percentages are partially determined by values that you have selected (such as desired observation size, etc.), it is important to maintain this information for reporting purposes and for reusing your frequency table (see “Use Existing Frequency List” under Options).
External Dictionary File
This feature is currently only available when using MEH to search for 1-grams.
When this option is selected, MEH will create an external content coding dictionary file that may be used as a custom dictionary with RIOT Scan (this file can be very easily edited for use with LIWC 2007 as well). The dictionary created will be derived from the text that you are processing and accounts for conversions and lemmatization, if being used. Since the dictionary is derived from the text being processed, it may not necessarily reflect all possible words that you would like to include for a given category. For example, in this phrase:
Timothy was working on his work. It worked!
…the words “work”, “working”, and “worked” will all be able to be lemmatized and converted into the word “work”, and the custom dictionary will reflect this fact. However, since the word “works” does not appear in this phrase, MEH does not know that it will also be able to be a part of this dictionary category. As such, you may want to inspect your dictionary file after it is created and make any additions that you feel are necessary.
Important: The “Build Dictionary” feature of MEH is considerably slower than other features of the software. This is because MEH currently goes through every file and tries every combination of possibilities with your data as a way to try to make the most complete version of a dictionary possible. Making this feature faster and more flexible is on the “to do” list.
Verbose Output
The verbose output generated by MEH is similar to output that you might see created by standard content coding software, such as LIWC or RIOT Scan. Observations are numbered and accompanied by filenames, along with the segment numbers of each file (where applicable). The DictPercent variable reflects to total percentage of each observation that was captured by the searched-for N-grams (specified by the user; see the options page for more information). Additionally, values in each column represent the frequency of each N-gram, represented as a percentage of each observation’s word count (remember that word count is calculated after conversions and lemmatization have been applied).
Of note, the columns are pre-sorted (from highest to lowest) according to the percentage of observations containing the corresponding N-gram.
Binary Output
The binary output is identical to the verbose output, however, scores for each N-gram are converted into simple presence/absence scores. Values of 1 and 0 signify the corresponding N-gram’s presence and absence, respectively, for a given observation. As per standard recommendations (e.g., Chung & Pennebaker, 2008), the binary output is often preferred over the verbose output for the meaning extraction method.
DTM (Document Term Matrix) Output
The document term matrix output is similar to the binary and the verbose outputs, however, it provides the raw counts for each n-gram per observation. This output file can easily be used for the purpose of something like Latent Dirichlet Allocation using the “topicmodels” package in R.
If you are new to LDA, or you simply need an R script that makes LDA easy to use with MEH’s DTM output, I have written one that you may freely use. It can be downloaded here.
Term Frequency – Inverse Document Frequency (TF-IDF) Output
This output is derived from a combination of the DTM output and the inverse document frequency (IDF) data that is generated with the frequency list. This same data can be calculated manually from other MEH output, however, it’s always nice to have software do the work for us. If you are unfamiliar with the concept behind tf-idf, a great primer page is located here.
Edge Matrices / Node Edge List Output
These output files are experimental in their current form — use with caution, as they have not been thoroughly examined and tested. These matrices and node/edge lists are raw co-occurrences between the different n-grams. The node list and edge lists are specifically designed to be loaded into Gephi, a network analysis tool. In cases where there are different numbers of co-occurring n-grams, the smaller value is used. For example, if the word “CAT” is used 3 times, and the word “HAT” is used 5 times, this is treated as 3 co-occurrences.
Note: I’ve included an R script to automatically process network data files and extract some data for each network into a single .csv file. This can be used to directly compare the structure of networks, etc. See the R script here: MEH Network Analysis.R
MEH WITH OTHER LANGUAGES
Recently, MEH has been updated to be able to handle virtually any language that your computer can properly display/interpret. To analyze texts that are in a language not listed in the Language dropdown menu, you only need to complete two steps.
1. Using the Select Text Encoding dropdown menu (located under the Text Handling Options menu), choose the proper encoding for your text files. For example, if you want to analyze Arabic texts, you will likely want to use the UTF-8 or UTF-16 encoding option. If the language that you want to analyze is the same as your computer’s default language, it is likely that the correct encoding is already selected by default.
2. Return to the Text Handling Options menu. Under the Language dropdown menu, select Other Language — the language selected by default will always be English. Make sure that the Use LemmaGen Lemmatization checkbox is unchecked.
That’s it! At the current time, MEH does not include default stop lists and default conversions for most languages on the planet (there’s a lot of them!). Additionally, lemmatization cannot be done on languages not included in the Language menu. You will need to create your own stop list and conversions (which can be used to lemmatize manually) for any language not included in MEH by default. I recommend ranks.nl as a good starting point for stop lists.
If you would like for me to add a default stop list and a default conversion list for a specific language, please send me an e-mail.
ABOUT MEH
The Meaning Extraction Helper (MEH) was created by Ryan L. Boyd in order to facilitate the speedy, accurate, and clean engagement in the meaning extraction method, which was first introduced in 2008 by Dr. Cindy K. Chung and Dr. James W. Pennebaker. Since then, the software has been expanded considerably to include things like term frequency-inverse document frequency data, output that can be used for other topic models (like LDA), and even semantic network graphs and other forms of distributed semantic representations.
Comments, questions, and feedback are always welcome!
The proper citation for the Meaning Extraction Helper is:
Boyd, R. L. (2018). MEH: Meaning Extraction Helper (Version 1.4.31) [Software]. Available from https://www.ryanboyd.io/software/meh
Dedication
This software is dedicated to the memory of Jennifer J. Malin. If you find the Meaning Extraction Helper of use in your work, please consider donating to the Jennifer Malin Endowment.
Contributors
If you would like to contribute to the Meaning Extraction Project, please send an e-mail to Ryan L. Boyd. The following individuals have helped to contribute to this project in various capacities, and are due proper thanks:
Kate Blackburn
Cindy K. Chung
Elif Ikizer
Paola Pasca
James W. Pennebaker
Nairán Ramírez-Esparza
Changelog:
2018-08-18 – Uploaded version 2.0.0 beta. Complete rebuild of MEH from the ground up. The older version is still available for time being while the transition is made.
2018-08-01 – Uploaded version 1.4.31. Fixed a bug where a double-space in the “Dictionary Words” box could cause the program to stall. Special thanks to Kate Blackburn and Sarah Seraj for their help in identifying this bug.
2018-08-01 – Uploaded version 1.4.30 and portable version. Fixed a bug wherein the last word of a text could get skipped when aggregating into a document x feature table. Special thanks to Roman Taraban for bringing this bug to my attention.
2017-12-11 – Uploaded version 1.4.20 and portable version. Fixed a bug with the “conversions” feature that would, depending on setup, cause the software to incorrectly perform conversions within words as well as on whole words. This version should fix the problem. Special thanks to Caroline Hamilton for the heads-up!
2017-05-04 – Uploaded version 1.4.15 and portable version. This latest version is built under .NET framework 4.6.1. In preliminary tests, this new version is slightly more efficient, but there shouldn’t be any obvious differences as a function of the framework. This was done primarily to keep everything relatively up to date with newer systems. Additionally, it is now possible to analyze texts for up to 10-grams. Keep in mind that this is only feasible on systems with a lot of RAM. If analyzing texts for a large “n” in your n-grams, you’ll want to make sure that you take full advantage of the “Prune Low Baserate N-Grams” feature of the software.
2016-07-19 – Uploaded version 1.4.14 and portable version. Removed the “e-mail when completed” feature, as nobody ever used it. Added the ability to choose how many processors to use for frequency list creation.
2016-04-27 – Uploaded 1.4.13 and portable version. Added the “.dic” extension to dictionary files instead of “.txt”. This makes the dictionary files compatible with LIWC2015 “out of the box”. Added the word “kinnen” to the default German stoplist (thanks to Thomas Zapf-Schramm). Removed an old debug conditional that was accidentally retained from a previous version. The bug did not affect output, but would raise “True” message boxes when the word “grandma” was included in the dictionary word list and certain other conditions were met. Random, I know — it’s been long enough to where I don’t even remember why that was the word used for debugging. Also, updated the splash screen to reflect the correct copyright dates (2016 is now included).
2016-04-26 – Uploaded 1.4.12 and portable version. Implemented a new system to output the final datasets for MEH (e.g., binary, verbose, etc.). This method keeps file streams open while rescanning for frequencies. This method implements a far more efficient use of the hard drive and resources. This stage of the analysis should now be much, much faster, particularly for massive datasets.
2016-04-25 – Uploaded 1.4.10 and portable version. Testing a new system for the creation of term frequency files that is parallelized. Preliminary tests for this version show that this step can run up to 75% faster than the previous versions. I’m not sure how stable this implementation will be, so please keep me notified of any bugs that you encounter.
2016-04-14 – Uploaded 1.4.08 and portable version. Fixed a bug where DTM and TF-IDF output would be incorrect when using the “European Format” output option. Special thanks to Thomas Zapf-Schramm for bringing this bug to my attention and figuring out the cause.
2016-03-29 – Uploaded 1.4.07 and portable version. Fixed a bug in the MEH Wizard that would not scan subdirectories within the Wizard when it had been explicitly requested by the user.
2016-03-01 – Uploaded 1.4.06 and portable version. Fixed a bug in the MEH Wizard that would select “Scan Subfolders” regardless of what the user chose.
2015-12-13 – Uploaded 1.4.05 and portable version. Fixed a bug that prevented the standard frequency outputs (i.e., binary, verbose, dtm, etc.) from being properly created under certain conditions. It us not yet certain if this bug will persist under other conditions, but testing will happen soon to ensure that everything works as expected. Fixed many more small UI bugs, fixed a bug that caused frequency outputs to be run extremely slowly when “skip-gram” network edge detection was being run.
2015-12-12 – Uploaded 1.4.04 and portable version. Fixed a minor UI bug. In the previous version, MEH would not correctly recognize the “On the Fly folder indexing” option and the “Skip files that cannot be read” option. This has now been fixed.
2015-12-08 – Uploaded 1.4.03 and portable version. Fixed some bugs with the interface that would prevent some options from disabling/re-enabling. Updated the Turkish stop list and conversions list, thanks to Elif Ikizer. Completely reworked the semantic network data engine to include only raw word counts, as well as an optional “skip-gram” style method.
2015-11-23 – Uploaded 1.4.01 and portable version. Added some extra information to the MEH Wizard to help users understand what the software does “out of the box”. Added an R script to run Semantic Network Analyses to the Understanding Output page.
2015-11-20 – Uploaded 1.4.00 and portable version. Added the new “MEH Wizard” to make setup and navigation of the software easier for new users. Somewhere in the past couple of months, the website developed an error that disallowed administration, so I had to scrap the website and reinstall.
2015-09-23 – Uploaded 1.3.08 and portable version. Fixed a couple of mistakes in the default conversions for English. Added a blinking indicator to the Analyze button. Rewrote the conversions engine — the system is now up to 5x as fast. Fixed the “Scan Subfolders” option. Fixed an issue where MEH could still attempt to lemmatize text after selecting an unsupported language.
2015-09-21 – Uploaded 1.3.07 and portable version. Fixed an issue where file headers were being detached from the rest of the data.
2015-09-09 – Uploaded 1.3.06 and portable version. Finally solved the 32-bit vs 64-bit problem… hopefully. Special thanks to Kate Blackburn, Sanaz Talaifar, Anastasia Rigney, and Skylar Brannon for their help in getting to the bottom of this.
2015-09-02 – Rebuilt x64 versions of MEH 1.3.05. Hopefully, this will fix the issue that prevents the x64 version from successfully running on x64 PCs.
2015-09-01 – Uploaded version 1.3.05 and variants. Fixed a number of small interface bugs (e.g., inability to disable lemmatization, certain options becoming inaccessible after processing files). Added a feature that allows the user to process their stop list prior to conversions. Added a number of additional catches and fixes for when common memory issues arise.
2015-08-28 – Uploaded version 1.3.04 and portable version. Fixed a bug with the conversion system that would miss multi-word phrases.
2015-08-27 – Uploaded version 1.3.03 and portable version. Fixed an issue with the new frequency list generation code. Previous version would merge the first two lines of output together. Previous versions could also run into memory issues when processing datasets with extremely large numbers of n-grams. On 64-bit machines, this is now limited by how much data MEH can hold in your system’s memory, rather than a hard ~1.5 GB limit. This ~1.5 GB RAM limit is still in place on 32-bit machines however. Also, added the ability to rely exclusively on the Dictionary List, ignoring any n-grams that aren’t explicitly in this list.
2015-08-26 – Uploaded version 1.3.02 and portable version. Changed how the Frequency List is written to a file. The new way should minimize memory issues, particularly for large datasets and datasets with a lot of unique words. If you’ve experienced errors for no obvious reason while MEH is trying to write your Frequency List, this was likely the cause. Updating to the latest version is recommended.
2015-08-24 – Uploaded version 1.3.01 and portable version. Fixed a bug where MEH was not actually changing the file encoding to what users selected from the dropdown menu. This is now resolved.
2015-08-13 – Uploaded version 1.3.0 and portable version. Complete interface overhaul — MEH is now considerably less cluttered than the previous version. Menus are now used for options, meaning that option settings can be reviewed during processing. Minor bug fixes. Added the “Dictionary Words” box and scrapped the older “Dictionary Mode”. The new interface has been tested pretty thoroughly. However, if you find any bugs or mistakes, please send me an e-mail.
2015-08-12 – Uploaded version 1.2.724 and portable version. Added all possible system encodings — MEH can now process almost any text file with any encoding. Added a splash screen. Thinking about ways to redesign the program layout so that it’s less cluttered and clunky looking.
2015-08-03 – Uploaded version 1.2.723 and portable version. Heavily modified the “create dictionary” engine. This new process is about 25% faster than previous versions. Note that this is still the slowest part of the entire application.
2015-07-21 – Uploaded version 1.2.722 and portable version. Changed data types used by MEH when compiling a combined frequency list. This process is now around 8x faster than previous versions (give or take), particularly when dealing with very large numbers of files in big datasets.
2015-07-20 – Uploaded version 1.2.721 and portable version. Changed word handling from uppercase to lowercase. This provides a small additional gain in performance, particularly when lemmatization is used. Output is now also in lowercase.
2015-07-19 – Uploaded version 1.2.72 and portable version. Lots of new changes and additions. The primary processing engine has had some small changes made to it in how it handles and searches for words as they are recognized. This process runs at essentially the same speed as before for smaller files, but exhibits speed gains of anywhere between about 3% and 15%+ for larger files. Added multiple segmentation options, including the use of Regular Expressions to segment incoming files. This is particularly useful for creating semantic network data, or splitting files by linebreaks. Changed how different pieces of data are handled throughout the process, which should lead to some more efficient file reading and string processing across the board.
2015-06-08 – Uploaded version 1.2.718 and portable version. Added the “Prune Low Baserate N-Grams” feature to the options menu.
2015-06-03 – Uploaded version 1.2.717 & portable version. Multiple users on Windows 8.1 have reported that MEH stopped working on their newer systems. This version is an update that should fix this issue. Please let me know if you continue to have issues with this update.
2015-05-21 – Uploaded version 1.2.716 & portable version. Fixed a bug that prevented aggregated network data from being output if any one of the four output types (binary, verbose, etc.) was not selected.
2015-05-08 – Uploaded version 1.2.715 & portable version. Reworked some of the network data generation algorithms for the file-by-file code. This new approach should use considerably less memory and run much more quickly. Added the word “thing” to the default English stop list. Changed a few option defaults.
2015-05-08 – Uploaded version 1.2.714 & portable version. The only change is that this version is built on .NET 4.5.2. Some users have been having issues with previous builds running on Windows 8 — this update should help this issue. Windows 7 users should ensure that they have this latest .NET version installed.
2015-05-06 – Uploaded version 1.2.713 & portable version. Fixed some minor bugs / typos in the code, but nothing that should result in different output than previous versions. Added the ability to generate individual network data for each file, including when segmentation is used. As before, this is all experimental and needs to be thoroughly checked.
2015-05-02 – Uploaded version 1.2.711 & portable version. Fixed a couple of minor bugs with the edge/node system. Cancellation should now work prior to matrix construction (not during yet — this will be added in the near future).
2015-05-02 – Uploaded version 1.2.710 & portable version. Changed the layout of the options forms. Changed the names of output files to be a bit more brief. Added a whole mess of output options in the form of weighted co-occurrence matrices derived from the standard output. These new output files are intended for use with semantic network analyses and software such as Gephi. These output files and format are experimental right now.
2015-04-30 – Uploaded version 1.2.705 & portable version. Fixed a ton of little bugs that have been pestering me for a while. Fixed a bug where the options form would reset if users made changes then opted to work from a pre-existing TF folder / frequency list. Fixed a potential bug for the progress bar to cause an error message. Fixed a problem where filenames that began or ended with whitespace would cause an error. Additionally, I have rewritten the frequency table building process — this process no longer relies on a binary serializer as it was running into problems with larger files. This new system should also help minimize read/write errors during the term frequency combination process. This new system should also be more RAM-friendly, as it no longer requires two entire subsets to be loaded into RAM at the same time in order to combine them after the first pass.
2015-04-28 – Uploaded version 1.2.703 & portable version. Added an option that allows the user to specify the number of decimal places they would like for verbose and tf-idf outputs. Smaller values will lose a small amount of precision (e.g., .00054 versus .0005432186), however, the data files will take up considerably less hard drive space.
2015-04-27 – Uploaded version 1.2.702 and the portable variant. First, removed an annoying message that would pop up while building a frequency list for every word — a holdover from the debugging process that was improperly removed. Second, added the option to get tf-idf output directly from MEH rather than having to manually calculate this information.
2015-04-26 – Uploaded version 1.2.7 and the portable variant. Numerous changes have been made. An option has been included to skip over read errors for datasets that might have multiple corrupt files. Several parts of the frequency list generation have been improved to reduce errors. Inverse document frequency (IDF), total number of included observations, and a raw count of observations in which each n-gram occurs are now included in the frequency list output. This new frequency list system will not read older frequency lists unless modified such that the header looks like that generated by version 1.2.7. Please e-mail me if you have questions about reusing an old frequency list with this version of MEH.
2015-04-22 – Uploaded version 1.2.67 and the portable variant. Made a slight change that will correctly classify the alphabetical portion of numeric ranks as numbers. If you have been having words like “st”, “th”, and “nd” show up in your frequency list, these are likely the result of n-grams in your data like “1st”, “8th”, and “2nd” — the numeric component was cut off and correctly classifed, but not the remaining part of the word. This has been fixed in this current version — any numeric characters that are followed by letters are now treated entirely as a number.
2015-04-08 – Uploaded version 1.2.66 and the portable variant. Special thanks to Elif Ikizer for providing a Turkish conversion list and stop list. I have also decided to stop creating .NET 4.0 builds for Windows XP, as this takes precious additional time and I am not aware of any users who currently run Windows XP.
2015-02-10 – Uploaded version 1.2.65 and its variants. Added a “dictionary mode” that can be used to specify the specific N-grams that you would like MEH to search for in your text files. Moved the location of the “use pre-existing TDF and Frequency List” option to a more appropriate location. Minor changes to the internal formatting of some of the CSV output, should result in identical appearance.
2015-02-08 – Uploaded version 1.2.603 and its variants. Rewrote a substantial part of the frequency recombination engine. MEH now uses serialized binaries of objects created from each text file rather than writing to, then reading from and parsing, .txt files during this process. This should help to make this system faster and less processor intensive. Added some more words to the default English conversion list. Added an extra column in the frequency list that shows the frequency of n-grams for included observations in addition to the original overall frequency regardless of inclusion. Fixed the dictionary building system — a bug was introduced in a previous update that prevented the dictionary building system from working. This bug was not discovered until recently.
2015-01-31 – Uploaded version 1.2.602 and its variants. Fixed a bug with the “dynamically adjust values” recombination feature that could cause analyses to halt early.
2015-01-30 – Uploaded version 1.2.601 and its variants. Minor tweaks to the term frequency combination engine to help with overall completion speed.
2015-01-26 – Uploaded version 1.2.6 and its variants. A lot of changes, bugfixes, and new features. Updated the default Conversion list and Stop list for English. Updated default lists for Italian (special thanks to Paola Pasca). Fixed a bug where unchecking the [N-X]-gram feature would not actually disable this feature. Fixed a bug where searching for [N-X]-grams would incorrectly overemphasize values for words appearing at the beginning of files, which could result in erroneous frequency lists. Fixed a couple of small UI bugs that did not impact performance. Rewrote the entire engine for the “Building Combined Frequency List” stage of text analysis. This process should now be much, much faster than before. I also added several controls and features that allow users to tweak how this process works. Updated the citation year (this was also updated for a later uploaded of version 1.2.501). Other minor changes made to UI layout. Fixed a bug where cancelling during early stages would still result in MEH trying to sort a frequency list, resulting in a delayed cancellation.
2015-01-10 – Uploaded version 1.2.501 and its variants. Added the “e-mail notification” feature to the options available to users. If selected, this option will send you an e-mail when processing is complete, or when an error is encountered. Particularly useful if you want to know when text analysis has finished for a large dataset.
2014-12-30 – Uploaded version 1.2.5 and its variants. Major additions to this version include “big data” options such as subfolder scanning and on-the-fly folder indexing, as well as other options such [n-x]-grams, the ability to start from previous term-frequency folders to build a new frequency list, and so on. This update constitutes a major update.
2014-11-24 – Uploaded version 1.2.42 and its variants. Minor fixes made to UI code, no change in functionality.
2014-11-18 – Uploaded versions 1.2.41, 1.2.41 XP, and 1.2.41 portable. Fixed a bug that would cause MEH to rescan files for frequencies when these options were not explicitly selected, but the “build dictionary” option was selected.
2014-11-16 – Uploaded versions 1.2.4, 1.2.4 XP, and 1.2.4 portable. Fixed a bug that was preventing the “Use Existing Frequency List” feature from working correctly with the updated engine.
2014-11-13 – Uploaded versions 1.2.3, 1.2.3 XP, and 1.2.3 portable. More core changes to the engine. The new engine creates specific “NGram” objects that are handled more efficiently than before. Another extremely important point of speed increase occurs during the “sorting frequency list” and “observing observation percentages” phases of the procedure. Extremely large frequency lists from large datasets could often take many hours, and sometimes more than a day, to completely sort. New sorting procedures were implemented that are thousands of times faster than before. For example, a dataset that took MEH ~36 hours to sort the frequency list before now takes MEH less than a minute to properly sort.
2014-11-07 – Uploaded versions 1.2.0, 1.2.0 XP, and 1.2.0 portable. This release constitutes a major update. A complete list of changes includes:
- Minor changes made to fix a couple of issues that could lead to imprecision in rare cases
- A total engine rewrite for 2/3 of the program. Various benchmarking suggests that the time to complete a frequency analysis + rescan to create datasets is around 4x faster as a result of the engine rewrite. For larger datasets, speed increases may range from approximately 4x to 40+x than the previous version, depending on the size and nature of the dataset.
- MEH now generates term frequencies for each document and stores them in your output folder — it reuses this information for considerable speed gains. This also allows users to take this data and apply it in any way they see fit.
- MEH now allows you to choose the text encoding (for both input and output) that you would like to use. Currently, you can select from your system’s default (recommended in most cases), ASCII, and UTF-8. Other common encodings can be added by request.
2014-10-08 – Uploaded versions 1.1.2, 1.1.2 XP, and 1.1.2 portable. Changed the encoding used when reading in files from system default to UTF-8. This will allow users to analyze text files that have a Unicode encoding without problems, even when using an ANSI/ASCII default computer.
2014-09-18 – Uploaded version 1.1.11, 1.1.11 XP, and 1.1.11 portable. Two minor changes. I updated the “tab indexes” so that the “Tab” key navigates the interface more smoothly. I also added a very small number of default conversions that convert standard British spellings to United States spellings (e.g., “behaviour” to “behavior”). Americentric, I know — I am happy to remove these defaults if people disagree with their inclusion. Just let me know.
2014-09-13 – Uploaded version 1.1.1, 1.1.1 XP, and 1.1.1 portable. Made some significant changes in order to continue pushing MEH further in its “big data” capabilities. The “Files to Investigate” box is no longer present, as this feature was generally not useful when scanning huge folders full of .txt files. Small engine changes were made to allow better acquisition of file information as well as the capability to hold much more file information in memory. Before, MEH would choke on large numbers of files ( > 500,000, although exact numbers aren’t known). MEH 1.1.1 has been tested and confirmed working with a folder of 2.5 million files, although the current upper limit has not been tested.
2014-08-10 – Uploaded version 1.1.0, 1.1.0 XP, and 1.1.0 portable. Made changes to the engine that improve speed when rescanning for frequencies. Speed gains may be anywhere from trivial to around 20-25% during the rescanning phase depending on multiple factors such as word counts and the “n” selected for n-grams.
2014-07-05 – Uploaded version 1.0.91, 1.0.91 XP, and 1.0.91 portable. Fixed two small bugs that shouldn’t affect functionality for most users. One bug involved situations where only one word was extracted from an entire corpus that would cause text analysis to halt early. The second bug involved non-ASCII apostrophes and would allow partial words such as don(‘t) and wasn(‘t) to persist through analyses.
2014-06-17 – Uploaded version 1.0.9, 1.0.9 XP, and 1.0.9 portable. This new version is much more light on its feet, and no longer loads all text into memory prior to analysis. Rather, 1.0.9 reads text in on an “as needed” basis. This not only makes MEH incredibly less greedy with system resources, but also allows for the analysis of extremely large corpora. Essentially, the size of the corpus that can be processed by MEH is no longer limited by whether you can fit the entire thing into RAM all at once.
2014-06-16 – Added a link to tutorial slides on this page.
2014-05-28 – Uploaded version 1.0.81, 1.0.81 XP, and 1.0.81 portable. Fixed a minor bug introduced in the “Output Options” button. This would prevent full output from being generated if you had previously decided to only generate the frequency list.
2014-05-28 – Uploaded version 1.0.8, 1.0.8 XP, and 1.0.8 portable. Added “Output Options” button. This allows you to specify which types of output you would like; this helps to avoid unnecessary clutter and save some disk space when you don’t want all three primary types of output (Binary, Verbose, and DTM).
2014-05-27 – Uploaded version 1.0.7, 1.0.7 XP, and 1.0.7 portable. Added the “document term matrix” output to the default MEH output. This will expands MEH’s usefulness to analyses such as LDA.
2014-03-31 – Uploaded version 1.0.6 and 1.0.6 XP (not a portable version yet, but that will come soon). Increased the amount of text that can be placed in the “Conversion” and “Stop List” boxes. This allows for much, much larger lists that may come in useful if you have a massive list of conversions that you want to use (for example, if you want to perform lemmatization manually for an unsupported language).
2014-02-26 – Uploaded version 1.0.55 (and XP and portable versions). Updated the default stop list for Spanish words. Special thanks to Nairán Ramírez-Esparza for this stop list!
2014-02-25 – Uploaded version 1.0.54. Minor update to the “European Output” option. This fix should now generate output that is in full compliance with this format. Please let me know if this is not the case.
2014-01-12 – Uploaded version 1.0.53. Minor updates to default conversion list. Fixed a small bug that could cause 2+-grams to halt while rescanning for frequencies. Added a Windows XP version.
2013-11-17 – Uploaded version 1.0.52. Minor updates to English stop list. No change in functionality.
2013-11-14 – Uploaded version 1.0.51. Added a word to the default English Conversions list. Changed tab index order for better navigation.
2013-11-13 – Uploaded version 1.0.5. Frequency list now contains metadata for convenience, reuse, and reporting. Added the “Use Existing Frequency List” option, allowing users to reuse a previously-generated frequency list, thus bypassing this stage of analysis if desired. Greatly improved sorting algorithms for the “Sort Freq / Dictionary Output” option — this saves a very large amount of time and processing power, especially for larger projects. Improved algorithm for dictionary construction, which shaves some extra processing time off of this procedure.
2013-10-24 – Uploaded version 1.0.2. A lot of major changes. Output is now printed in an iterative fashion to conserve system resources. Minimum observation percentage is now used rather than “Scan for X number of N-Grams” for better precision and less work for the user. Other small changes implemented for resource conservation and simplicity, some text changed for better usability. Removed some words from the default English stop words list that would usually be of interest to researchers.
2013-10-16 – Uploaded version 1.0.1. Fixed an issue where qqNUMBERqq was being ignored as a stop list entry when lemmatization was disabled.
2013-10-15 – Uploaded version 1.0.0. Updated MEH to .NET version 4.5. MEH has access to a greater amount of RAM, allowing for the processing of much larger quantities of text.
2013-10-12 – Uploaded version 0.9.987. Fixed a bug that would overload the building of custom dictionary files during reconstrual. Updating to this latest version is recommended.
2013-10-12 – Uploaded version 0.9.986. Additional default English conversions added, most of which are common misspellings.
2013-10-11 – Uploaded version 0.9.985. Custom dictionary file is now reconstrued to alphabetical order for easier reading / editing. Added more default conversions for the English language.
2013-10-11 – Uploaded version 0.9.98. Built in a safeguard that prevents the possibility of users”overscanning” text when building a custom dictionary file by trying to build a dictionary file from more N-grams than what actually exists in the text being processed.
2013-10-07 – Uploaded version 0.9.97. This version is able to build a custom dictionary file (compatible with RIOT Scan), derived from the text being processed. This feature is useful for combining word categories and applying themes to new samples of text.
2013-10-01 – Uploaded version 0.9.96. Slight change in interface updating and a small efficiency tweak. No changes in functionality whatsoever.
2013-09-27 – Uploaded version 0.9.95. Major overhaul of the conversion system. It is now much more flexible and should work for multiple languages. Implemented a feature to create output in either standard or European .csv format.
2013-09-27 – Uploaded version 0.9.9. Added a few more stop lists for other languages.
2013-09-26 – Uploaded version 0.9.8. Implemented support for multiple language lemmatization. Added default stop word lists for all corresponding languages (lists derived from ranks.nl and other places). Languages that require unicode encoding (such as Russian and Bulgarian) need to be thoroughly tested by someone who is fluent in these languages. I am hoping to eventually add better stop word lists for all supported languages.
2013-09-18 – Uploaded version 0.9.7. Implemented N-gram features across the board. Moderate interface redesign for better tracking / useability.
2013-09-18 – Uploaded version 0.9.6. Fixed a small bug that could, in rare circumstances, cause an overly conservative word search.
2013-09-17 – Uploaded version 0.9.5. Files on the desktop are now much more easily accessible.
2013-09-13 – Uploaded the first version of this page, uploaded MEH 0.9.4. Special thanks to Dr. Cindy Chung for her guidance in performing the Meaning Extraction Method.